Is GOOG's TPU Mania The Second "Deekseek Moment"?
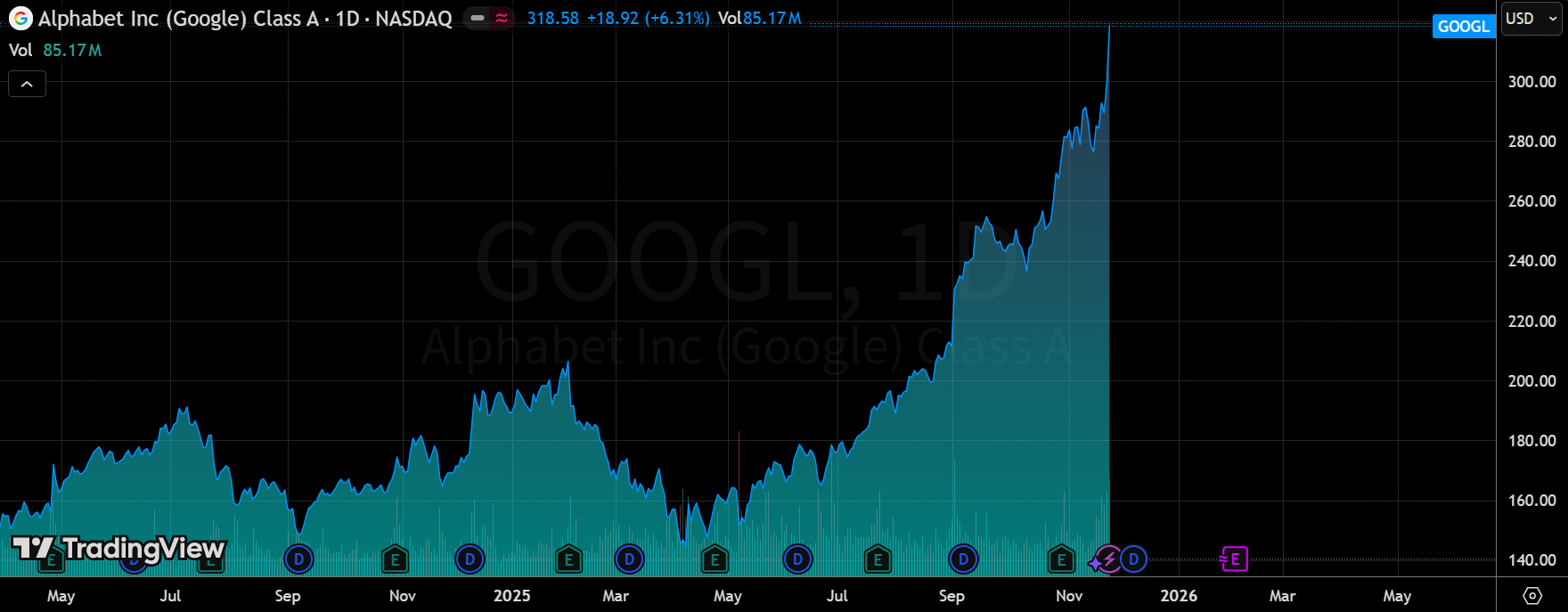
Over the past 48 hours, one of the biggest stories in the entire AI sector has been the explosive move in Google-related assets. $Alphabet(GOOGL)$ / $Alphabet(GOOG)$ shares ripped higher by more than 6% in regular trading and tacked on another ~2% after-hours on reports that Meta is in talks for a massive multi-billion-dollar TPU order. Meanwhile, $NVIDIA(NVDA)$ and $Advanced Micro Devices(AMD)$ barely budged — a stark contrast to what we usually see when AI hype hits.
This isn’t being driven by a single headline. It’s the culmination of several developments that are forcing the market to completely re-price the cost structure of both training and inference:
Gemini 3’s breakthrough performance (largely trained on TPUs)
The new “TPU@Premises” on-premise deployment program
Active negotiations with Meta, Anthropic, OpenAI, and a long list of financial/quant firms for huge TPU clusters
Investors are suddenly waking up to the idea that Google’s Tensor Processing Units (TPUs) are no longer just an internal Google tool — they’re becoming a genuine, industry-grade alternative to NVIDIA GPUs. The TPU supply-chain names got absolutely torched higher: $Lumentum(LITE)$ +17% to all-time highs, $Celestica(CLS)$ +15%, $Broadcom(AVGO)$ +11% (its 10th-best single day ever).
This feels eerily similar — but potentially much bigger — than the “compute price collapse” we saw at the beginning of 2025 when China’s DeepSeek shocked the market with ultra-low-cost training. Back then, NVDA dropped ~18% in a week as the street realized massive models could be trained for pennies on the dollar. Today, Google is delivering the same message, only from the demand side and with a full-stack ecosystem behind it.
Three Big Takeaways the Market Is Pricing In Right Now
1. TPUs are graduating from “Google-only” to “real GPU alternative”
Gemini 3 has become the hardest possible endorsement of the TPU training stack. Independent testers and industry insiders are saying its reasoning, speed, and scaling put it on par with — or ahead of — GPT-4-class models, and it was trained almost entirely on TPUs.
That single data point matters because it proves:
TPU offers better performance-per-watt than current GPUs
Cost control at hyperscale is dramatically better in large TPU clusters
Google’s software stack (Jax + the new TPU Command Center) has finally reached enterprise-grade readiness
Investors looked at the benchmarks, looked at Alphabet’s surging stock, and concluded: “The commercial ceiling for TPUs just got a lot higher.”
More importantly, Google flipped the business model on its head. Instead of forcing everyone into Google Cloud to rent TPUs, the new TPU@Premises program ships the iron straight into customers’ own data centers. Meta is reportedly discussing a multi-billion-dollar deployment starting in 2027. If even one of NVIDIA’s marquee hyperscaler customers starts shifting 10–15% of spend to TPUs, that’s real revenue at risk for Santa Clara.
And the kicker: Google just open-sourced enough of the software stack (TPU Command Center now works natively with PyTorch) that developers no longer have to rewrite everything in JAX. For the first time, TPU feels like just another accelerator you can drop into an existing PyTorch workflow — exactly the kind of friction-removal that erodes CUDA’s lock-in over time.

2. This feels like DeepSeek 2.0 — only broader and stickier
January 2025: DeepSeek shows the world you can train frontier models for a fraction of what everyone assumed → pure supply-side shock → NVDA and the entire HBM food chain get smoked.
November 2025: Google shows the world you can train AND infer at dramatically lower cost and power, and you can put the hardware wherever you want → demand-side shock from the biggest buyers on the planet.
The scope is wider:
DeepSeek only attacked training spend. TPUs hit both training and inference.
DeepSeek was a one-off model; TPU shift is driven by Meta, OpenAI, Anthropic, every quant shop, European cloud providers, and banks. When the buyers move, capex re-pricing tends to be structural and multi-year.
Power efficiency is becoming the new battleground. Data centers are literally running out of electricity. If TPU delivers 20–30% lower cost per token and 15–25% less power at full load, the ROI math flips fast.

3. We’re moving from “best chip” to “best platform”
NVIDIA’s moat has always been GPU performance + CUDA + NVLink/NVSwitch + the whole software compiler empire.
Google is now fielding a complete counter-offer:
Hardware that can train the biggest models
PyTorch compatibility + enterprise control via on-prem
Hyperscale cloud option for anyone who still wants managed service
And the best power envelope in the industry
This is starting to look like the x86 vs ARM transition in mobile all over again: two complete, vertically integrated platforms duking it out for the multi-trillion-dollar AI infrastructure pie.
Bottom Line
The TPU heat we’re seeing right now is probably just the opening act. If in the next few quarters we get confirmation that Meta or OpenAI have moved even a modest portion of their roadmap onto TPUs — and Google keeps opening the software kimono — then NVIDIA’s pricing power faces real, sustained downward pressure for the first time.
The era of a single company dictating the pace of AI capex may be coming to an end. The war is no longer just about the fastest chip. It’s about who owns the platform.
TPU mania is just getting started
Disclaimer: Investing carries risk. This is not financial advice. The above content should not be regarded as an offer, recommendation, or solicitation on acquiring or disposing of any financial products, any associated discussions, comments, or posts by author or other users should not be considered as such either. It is solely for general information purpose only, which does not consider your own investment objectives, financial situations or needs. TTM assumes no responsibility or warranty for the accuracy and completeness of the information, investors should do their own research and may seek professional advice before investing.
Google